Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod.
Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod.
Charlie
Jun 21, 2026

A ticketing platform looks like a shopping cart with seats. It isn't. The hard part is the 30 seconds when ten thousand people try to buy the same five hundred seats, and your job is to sell each one exactly once.
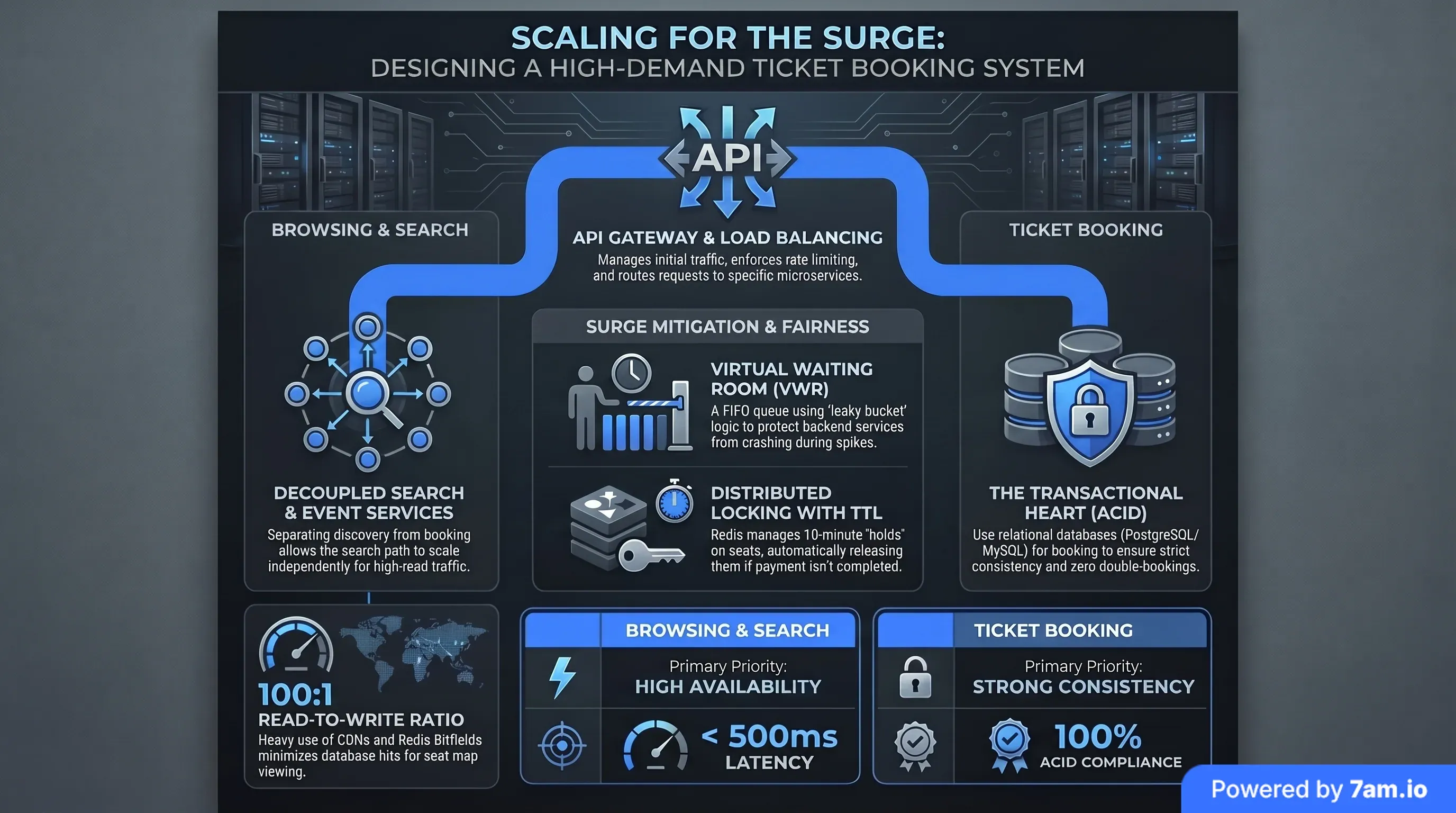
That single requirement, sell each seat once and only once, drags you into the deepest end of distributed systems. A normal web app is read-heavy and forgiving. A ticketing platform is read-heavy for browsing and brutally write-contended for buying, and those two jobs fight each other inside the same database.
Browsing an event is cheap. The performer, the venue, the door times: none of it changes, so you cache it hard and serve millions of views off a CDN. Buying is the opposite. Every purchase is a fight over a shrinking pool of inventory, and every fighter wants the same row in your database at the same millisecond. You are building a system that has to stay calm while a stadium's worth of people all reach for the last seat together.
Most teams scope the browsing app, see how easy it is, and price the whole build off that. Then the first real on-sale arrives and the booking path, the 5% of the system nobody stress-tested, is the part that decides whether you have a business. If you are still weighing whether to build or buy a platform, this is the part of the decision that actually matters.
Without protection, you oversell. Two people pay for seat 14F, both get a confirmation email, and one of them finds someone already sitting there on the night. That is the double-booking problem, and it is the central integrity requirement of the entire platform.
Here is how it happens. Two requests read the seat at the same moment. Both see "available." Both write "sold." Classic race condition. The database did exactly what each request asked. It just didn't know the two requests were about the same seat, because nothing told it to stop and check.
You cannot solve this by being careful in your application code. By the time your code has read the seat and decided it's free, another process has already taken it. The fix has to live where the data lives, inside the transaction, at the moment of the write. And that is where the genuinely hard engineering starts, because every method of stopping a race condition costs you something else you also need.
There are four real strategies, and not one of them is free. You can lock the row, you can mark it reserved with a timer, you can hold a lock in Redis, or you can model every seat as its own row. Each one trades consistency against speed, and the trade hurts somewhere.
Pessimistic locking is the obvious one. You run SELECT FOR UPDATE and the database refuses to let anyone else touch that row until you're done. Rock-solid consistency. Also a disaster at scale, because when a million people fight over the same rows, those locks pile up, the database CPU climbs, and the whole on-sale grinds. It's the right tool for a 200-seat theatre and the wrong tool for a stadium.
The status-plus-expiration approach feels friendlier. You flag the seat "reserved" with a ten-minute timer and let a background job sweep up the ones that expire. Now the buyer sees a countdown, which is good UX. But if that cleanup job lags, you get zombie reservations: seats locked by people who wandered off, invisible inventory you can't sell. The smarter version doesn't trust the sweeper at all. It treats a seat as available if it's either free or reserved-but-expired, checked at read time, so a slow cleanup job can't take your event hostage.
Then there's the Redis distributed lock. Fast, in-memory, auto-expiring, and it keeps the contention off your main database. The catch is brutal in its simplicity: if that cache restarts mid-sale, every active reservation vanishes at once. The database stays consistent, but thousands of people get kicked back to the start of the queue together. The full set of trade-offs is in the table below.
| Approach | How it prevents overselling | Main failure mode | Performance at on-sale scale | When to use |
|---|---|---|---|---|
Pessimistic locking (SELECT FOR UPDATE) |
Row-level lock; no other process can touch the record until released | High contention; abandoned carts leave seats locked | Poor; millions fighting the same rows hammer the database CPU | Low-concurrency systems or very short transactions |
| Optimistic control with TTL | Short transactions set a "reserved" status and expiry; claim only if free or expired | Slow reads from heavy filtering; thundering herd when a pool empties | Moderate; lighter than locking but still loads the database | When you want reservation logic inside one relational database |
| Distributed lock (Redis) | Temporary cache key with a TTL; database updated only on payment | Cache restart drops every active reservation; TTL can expire mid-payment | Excellent; lock acquisition is in-memory and very fast | High-demand launches needing low latency at burst traffic |
| Virtual waiting queue | A choke point that admits users at the rate the backend can handle | Long waits frustrate users; queue and booking state must stay in sync | Very high; applies back-pressure and levels the load | Events where demand outruns capacity by orders of magnitude |
Pick any row in that table and you've accepted a failure mode. That's the point. There is no clean answer, only a set of compromises you have to understand well enough to choose between. This is the same reasoning that runs underneath choosing the right ticketing system at all.
Because a single quantity counter couldn't survive the contention, and the team found the real bottleneck wasn't where anyone expected. Shopify rebuilt inventory reservations around one row per sellable unit instead of one row with a number on it.
Think about what a counter forces. Every buyer has to update the same row, "200 left," "199 left," and they queue up behind each other to do it. One row, a million hands. Shopify's answer was to give every unit its own row and use Postgres and MySQL's SKIP LOCKED so a buyer just grabs any available row and skips the ones others are holding. No queue at the counter, because there is no counter.
The part that should worry anyone planning to build this themselves is what they found next. Their throughput ceiling wasn't CPU. It wasn't the locks. It was connection hold time, the seconds a business process kept a database connection open while it did other work. The fix involved tagging every query so they could see which process was starving the pool. This is a company with one of the best engineering teams on the planet, processing millions in sales a minute, and the thing that capped them was a problem most teams have never heard of. You don't find that bottleneck in a tutorial. You find it at 11pm during your first big on-sale, with customers watching.
The traffic does. In November 2022, Ticketmaster's Eras Tour on-sale pulled in roughly 14 million users to a system planned for 1.5 million, and absorbed about 3.5 billion system requests in a single day, four times its previous peak. The public sale was cancelled. The fallout helped convert a generation into antitrust sceptics and fed straight into a Department of Justice lawsuit.
This is the thundering herd, and it is a different problem from double-booking. Even if your locking is flawless, a flood like that will knock over the front door before anyone reaches a seat. The defence is a virtual waiting room: a gatekeeper that holds everyone in a digital queue, usually backed by a Redis sorted set, and admits them to the seat map only as fast as your backend can cope. Users watch their position update live over a websocket. The booking service flatly rejects any request from a session that hasn't been admitted yet.
Building one of these well is its own project. You're now running a real-time queue at stadium scale, keeping it in sync with your booking state, and making sure that when you admit the next thousand people, your inventory system can actually take them. Queue-it, the vendor that runs Ticketmaster's queue, has reported single events drawing more than ten thousand visitors a minute before the sale even starts. That is the load you are signing up to engineer for, on your own, the first time you run a hot show.
Because once you charge a card, you've done something you cannot undo with a database rollback. Stripe's engineers call it a foreign state mutation. You've reached outside your own walls and changed a system you don't control, and now you have to never lose track of it.
Picture the failure. A buyer's reservation has a ten-minute timer. Their payment goes through at minute eleven, just after the timer expired and a second person grabbed the seat. Now you've charged someone for a seat they can't have, and you owe an automatic refund and an apology. The seat-locking problem and the payment problem are tangled together, and the tangle is where money leaks.
The defence is idempotency keys, and they are not optional in a ticketing system. Every payment request carries a unique key. The server records that key and its result, so if the request is retried, from a flaky phone connection, a double-tap, a network blip, it returns the saved result instead of charging again. Brandur Leach, who wrote Stripe's reference implementation, lays out the database schema, the transaction phases, and the recovery points needed to get it right. It is several hundred lines of careful, boring, mission-critical code that exists purely so one nervous buyer hammering the pay button doesn't get charged five times. Getting payouts right on top of that, making sure organisers actually get paid cleanly, is a whole second layer on the same foundation.
The door is where a different failure shows up, and it's just as public. At Bad Bunny's 2022 Mexico City shows, a wave of fake tickets caused the access-control system to stutter, and real ticket holders were turned away at the gate. The on-sale can be perfect and you can still fail in the last ten metres.
Scanning at scale is its own engineering problem. You need to validate thousands of tickets a minute, reject duplicates and fakes instantly, and keep working when the venue wifi drops, which it will. That usually means offline-capable scanners syncing to a shared source of truth, conflict resolution when two gates scan related tickets at once, and a fraud check fast enough to not hold up a queue of cold, impatient punters. The teams that build smoother entry and scanning treat the gate as a hard real-time system. Most homegrown builds treat it as plumbing, and find out the difference on a wet night with 3,000 people in the car park.
Build, and you're not buying a feature list. You're hiring a team to solve concurrency, queuing, payment idempotency, fraud, and access control, and to keep solving them every time a show goes hot. A custom platform runs well into six figures to build and keeps billing you in maintenance and operations long after launch. None of that money buys you a moment's safety on the night the seats actually sell.
The honest read is that the features are the easy 80%. The hard 20%, the part that decides whether your brand survives its first viral on-sale, is exactly the part a proven platform has already paid for in outages, post-mortems, and years of scar tissue. Buying a white-label platform you run under your own brand means you get the brand, the customer relationship, and the margin, without personally owning the distributed-systems problem. You still keep control of your brand and your data. You just don't have to learn what connection hold time means at the worst possible moment. The full money side of that call is in the unit economics of running a ticketing company.
A ticketing platform is one of the hardest small systems you can build, because it has to sell each seat exactly once while the whole internet reaches for it at the same time. Race conditions, thundering-herd traffic, payment idempotency, and door-scanning fraud are all separate problems, and you have to solve all of them before your first big show, not after.
For almost everyone launching a ticketing brand, that maths points one way. Own the brand and the audience, and let a platform that has already survived the outages own the engineering. 7am runs that infrastructure so you can put your name on the front and sell with confidence on the night it counts.
Explore More
View All


